奇异值分解(Singular Value Decomposition,SVD)方法被用于揭示不同气候变量之间可能存在的关系。该方法描述了每个变量变化的主要特征,还可以捕获了两个场之间的主要时空相关结构。
这里我们通过xMCA库来实现SVD方法,该库可以通过以下指令来安装:
1 | pip install xmca |
这里我将通过大致再现”Changes of climate extremes of temperature and precipitation in summer in eastern China associated with changes in atmospheric circulation in East Asia during 1960–2008“这篇论文中的SVD示例(数据与极端定义与原文不同,但结论基本一致,仅供参考)。简单来说,该文章通过SVD分析了中国区域夏季极端高温和极端降水日数的时空变化关系,体现了一种南涝北旱模态的年代际变化。这里我将通过中国CN05.1逐日最高气温和降水的1°分辨率格点数据集(我不提供该数据,我想大部分做气候的人应该都有这套资料),并以90百分位阈值的定义来识别极端高温和极端降水。
首先引入相关的库:
1 | import numpy as np |
读取文件并计算极端日数:
1 | f_prec = xr.open_dataset('/mnt/f/CN05_STATIONS/CN05.1/1961-2017/daily/1/CN05.1_Pre_1961_2017_daily_1x1.nc') |
这里需要强调的是,因为我使用的是xMCA中关于DataArray的方法,所以需要将最终的数据维度修改命名为”time,lat,lon”格式。如果使用的xMCA中关于array的方法,那直接传入ndarray即可。接下来将计算好的极端高温和降水日数放进SVD中(两个数组的形状均为:年份,纬度,经度。表示每年每个格点的极端天数;实际上与EOF类似)。
接下来是SVD部分:
1 | ##############SVD################## |
svd.heterogeneous_patterns()用于获取异构空间场,svd.pcs()为获取时间系数。
至此,即可进行SVD结果的可视化。
1 | fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14, 6), subplot_kw={'projection': ccrs.PlateCarree()}) |
输出的异构场het_patterns是一个tuple对象,het_patterns[0]是tuple中存放的一个字典对象,这个字典对象包含了左场和右场,所以我们通过[‘right’]和[‘left’]选出来左右场;最后[:,:,0]的目的是选出第一个模态。这两个场是DataArray对象,包含经纬度信息,所以可以直接使用Xarray中的画图方法。这也是我推荐使用xmca.xarray而不是xmca.array的原因。pcs直接是字典对象了,所以不需要[0]解开tuple。
图形输出结果:
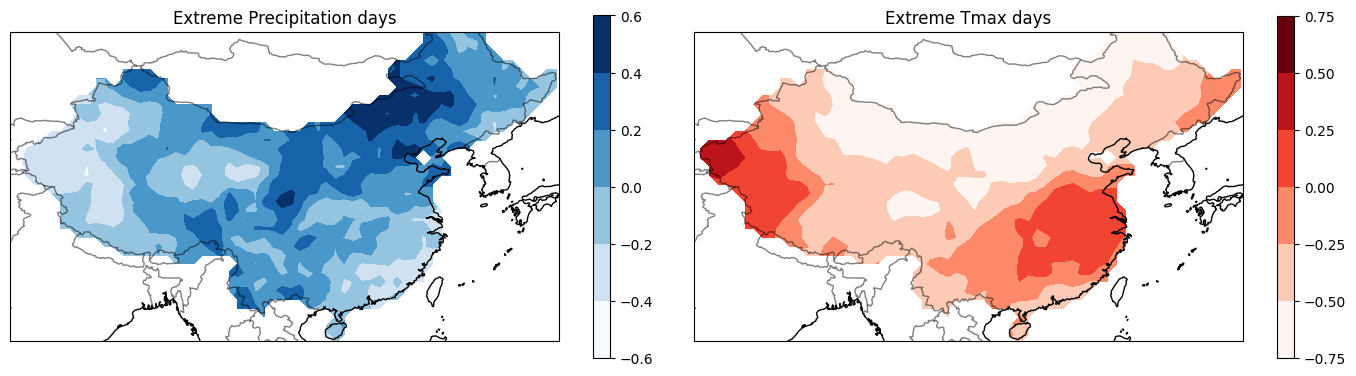
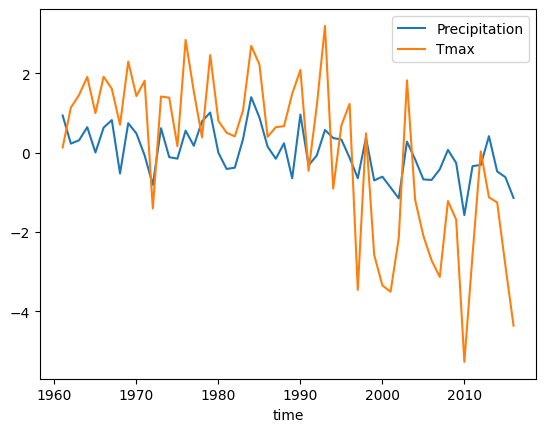
可以看出很显著的降水高温南北反相的特征,并且PC序列在90年代后出现显著趋势,与文章中的结果基本一致。